By : ATHIRAH BT ZAHARUDIN
Below are a few notes about Pipelining
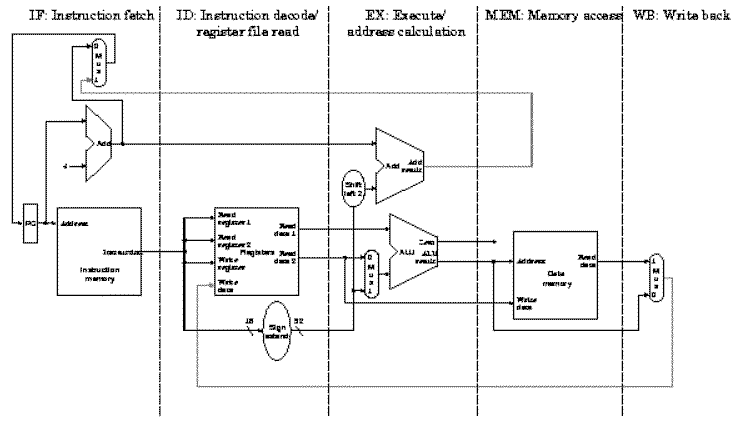
}Five
stages, one step per stage
1-IF:
Instruction fetch from memory
Fetch a new instruction every cycle
• Current PC is index to instruction memory
• Increment the PC at end of cycle (assume no branches for now)
Write values of interest to pipeline register (IF/ID)
• Instruction bits (for later decoding)
• PC+4 (for later computing branch targets)
2-ID:
Instruction decode & register read
On every cycle:
• Read IF/ID pipeline register to get instruction bits
• Decode instruction, generate control signals
• Read from register file
Write values of interest to pipeline register (ID/EX)
• Control information, Rd index, immediates, offsets, …
• Contents of Ra, Rb
• PC+4 (for computing branch targets later)
3-EX:
Execute operation or calculate address
On every cycle:
• Read ID/EX pipeline register to get values and control bits
• Perform ALU operation
• Compute targets (PC+4+offset, etc.) in case this is a branch
• Decide if jump/branch should be taken
Write values of interest to pipeline register (EX/MEM)
• Control information, Rd index, …
• Result of ALU operation
• Value in case this is a memory store instruction
4-MEM:
Access memory operand
On every cycle:
• Read EX/MEM pipeline register to get values and control bits
• Perform memory load/store if needed
– address is ALU result
Write values of interest to pipeline register (MEM/WB)
• Control information, Rd index, …
• Result of memory operation
• Pass result of ALU operation
5-WB:
Write result back to register
On every cycle:
• Read MEM/WB pipeline register to get values and control bits
• Select value and write to register fill
PIPELINE ANALOGY
Pipelined
laundry: overlapping execution
◦Parallelism
improves performance

>Four loads:
>Speedup = 8/3.5 = 2.3

>Non-stop:
>Speedup= 2n/0.5n + 1.5 ≈ 4
= number of stages

Pipeline Processor
Pipeline Speed
>If
all stages are balanced
◦i.e.,
all take the same time
◦Time between instructionspipelined
= Time between instructionsnonpipeline
------------------------------------
Number of stage
>Speedup due to increased throughput
◦Latency (time for each instruction) does not decrease
>Ideally 5 stage pipeline should offer nearly fivefold improvement over the 800 ps nonpipelined time.
>If not balanced, speedup is less






0 comments:
Post a Comment